MNIST
salida = relu(dot(entrada.W)+b)
"En algun lugar lei que la mejor manera de aprender matematica en programacion es usando las operaciones en lineas de codigo"
Hoy quiero contarles acerca de las Redes Neuronales Artificiales. Pero en especial del Deep Learning.
Para comenzar dejenme explicarles el titulo. Es simplemente una operacion matematica escrita en una linea de codigo que dice algo asi: la salida es igual al producto "punto" de un tensor de entrada con un tensor W. A la matriz resultante de esa operacion (si! es matriz... entonces es un tensor de 2 ejes) se le suma el vector b (como habras deducido si es vector es de 1 solo eje). A TODO ese resultado se le aplica la funcion de activacion "relu", que basicamente nos va a decir si se activa o no la neurona.
Nos vamos a enfocar entonces en el "Hola Mundo" de las redes. Y eso es el conjunto
de datos MNIST.
Basicamente este conjunto es un conjunto de 60000 imagenes de imagenes de numeros manuscritos en blanco y negro (escala de grises) de tamaño 28 de alto por 28 de ancho.
A me olvidaba tambien hay otro conjunto de 10000 imagenes iguales que sirven como conjunto de prueba o testeo.
Las imagenes como dije representan numeros manuscritos que van del 0 al 9 y la idea es que mediante el conjunto de entrenamiento (60000 imagenes y sus correspondientes etiquetas) se pueda entrenar un modelo que logre predecir para cualquier etiqueta el numero que le corresponderia.
Pero antes crear el modelo, tengo que darte algunos datos:
- las etiquetas son matrices al igual que las imagenes. Eso quiere decir que ambos tienen 2 ejes.
- Las etiquetas estan en un tipo de dato uint8 o unsigned 8-bit integer traducido seria algo asi como numero entero sin signo de 8 bits y sirve para representar numeros que van de 0 a 255. Solo pueden ser positivos, 8 bits es 1 byte, cada bit puede ser 0 o 1 lo que deja representar 2^8 = 256 valores.
AHORA SI!
ARQUITECTURA DE LA RED.
Primero nos copiamos los datos MNIST:
from tensorflow.keras.datasets import mnist
from tensorflow import keras
from tensorflow.keras import layers
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()Despues tenemos que darle a los datos la forma que el modelo requiere. Y para eso vamos a pasar las matrices de las etiquetas de valores uint8 a valores float32, basicamente porque nos permite tener un rango mas amplio y permiten representar fracciones para calculos de alta precision. Ademas los vamos a escalar para que solo puedan tomar valores entre 0 y 1.
train_images = train_images.astype("float32") / 255
test_images = test_images.astype("float32") / 255
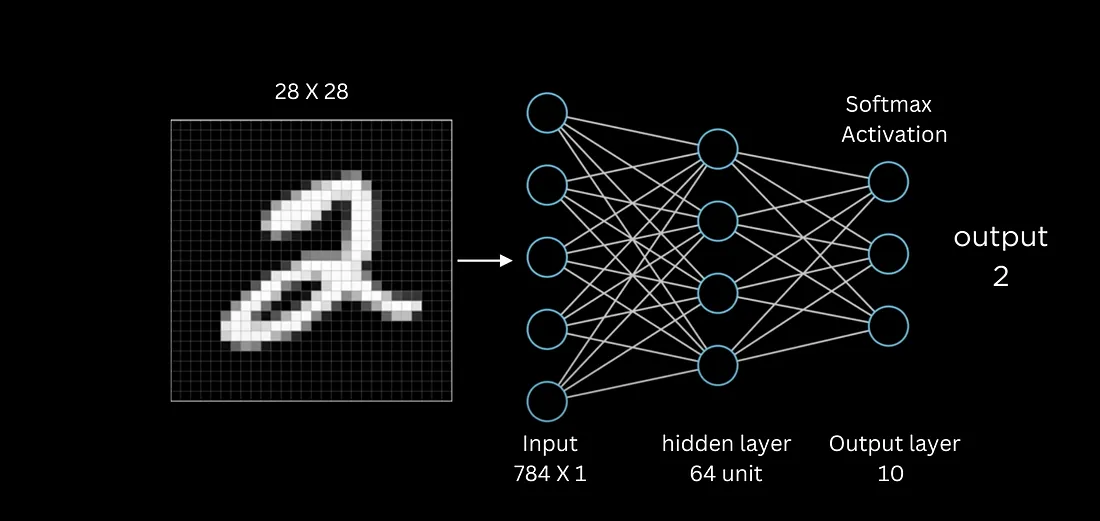
Continuamos con la creacion de la Red propiamente dicha es decir la conjuncion de capas que haran todo el trabajo duro con los datos que les ofrezcamos en este caso los datos del conjunto MNIST.
modelo = keras.Sequential([
layers.Flatten(input_shape=(28, 28)),
layers.Dense(256, activation="relu"),
layers.Dense(10, activation="softmax")
])
Creamos el Modelo (nuestra red) con Sequential le decimos como se van a estructurar las capas. Y dentro creamos 3 capas de las cuales la primera es de tipo flatten es decir que aplana a las imagenes de 28x28 a un vector de 784 pixeles. Esto es necesario porque las capas Densas es decir totalmente conectadas, esperan entradas de 1 sola dimension ademas, estas capas estan conectadas una de ellas con 256 vias y la otra con 10 vias. La primera se opera con una funcion relu y le segunda con una funcion softmax.
La idea con la utilizacion de capas es obtener mejores representaciones de los datos para que el objetivo buscado se logre.
Tambien necesitamos para que esto funcione 3 cosas mas: Un OPTIMIZADOR, Una FUNCION DE PERDIDA y claro analizar las METRICAS.
modelo.compile(optimizer="rmsprop",
loss="sparse_categorical_crossentropy",
metrics=["accuracy"])Necesitamos compilar tanto el optimizador, la funcion de perdida como las metricas.
Con esto estariamos ya en condiciones de entrenar nuestro modelo. Y lo hacemos de la siguiente manera.
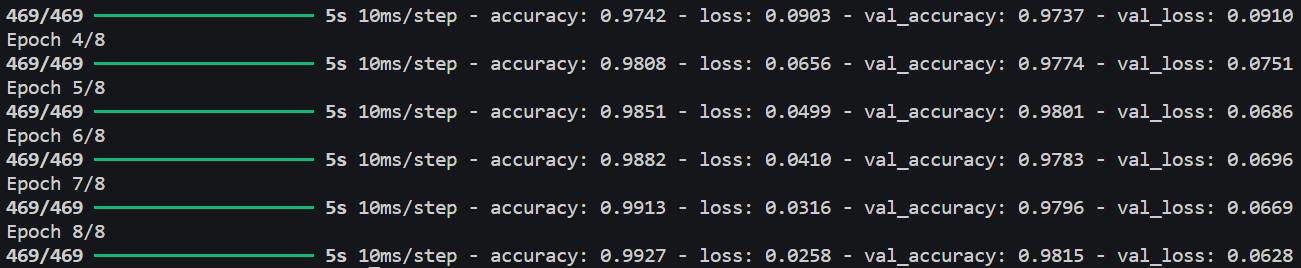
modelo.fit(train_images, train_labels, epochs=8, batch_size=128,
validation_data=(test_images, test_labels))El resultado de entrenar el modelo nos ofrecera informacion sobre el progreso de entrenamiento. El valor de perdida (loss) que para cada epoca nos dira cuan bien o mal el modelo esta ajustando sus predicciones a las etiquetas verdaderas. Por otro lado la precision (acurracy) es decir la cantidad de predicciones correctas que el modelo hace.
Y finalmente la perdida del conjunto de validacion para cada epoca y la precision del modelo para cada epoca del conjunto de validacion.
Abajo te mostramos un ejemplo del resultado de entrenar el modelo:
Bueno hagamos algunos experimentos mas:
modelo = load_model('mi_modelo.h5')
digitos_a_testear = test_images[99]
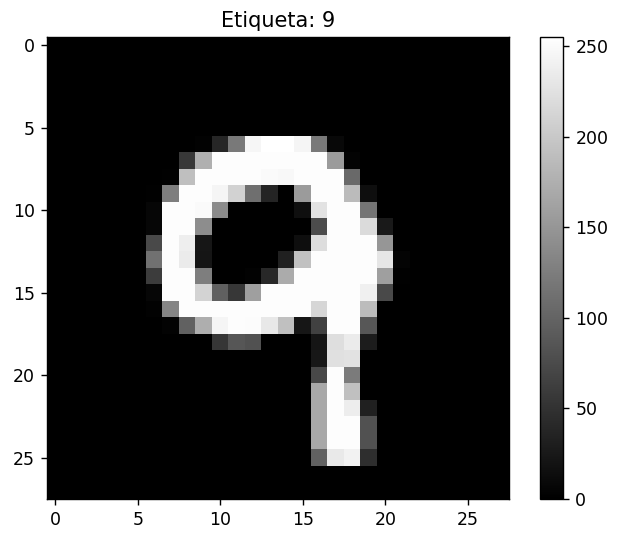
predicciones = modelo.predict(digitos_a_testear)Lo que estamos haciendo es probando que tal lo hace nuestro modelo entrenado "mi_modelo" con la imagen "99" del conjunto de imagenes de testeo.

El resultado son las probabilidades de que represente uno de los 9 digitos del conjunto y en este caso podemos ver que en la posicion 9 tenemos el 9.99% de probabilidades de que la imagen 99 sea un 9. Vamos a comprobarlo!
import matplotlib.pyplot as plt
imagen_a_mostrar = test_images[99]
etiqueta = test_labels[99]
plt.imshow(imagen_a_mostrar, cmap='gray')
plt.title(f'Etiqueta: {etiqueta}')
plt.colorbar()
plt.show()Lo que nos da como resultado que la imagen 99 corresponde a: